
This is a translation of this post in Russian written by Nikita Prokopov.
This post touches the topic of how functional programming approach helps us coders reduce the UI programming struggles.
There is not much difference in a process of developing interfaces for different platforms and it is a question of quantity then quality. Same problems, same solutions, free of extremums or even noticeable fluctuations. That's why the word “browser” in the title should not distract you: we are going to talk about architecture usable for any interfaces.
What we want is to learn how to build complex interfaces, such as having more than one story line happening on the screen. The traditional approach — spend a lot of time and get tired — works for now, but asks for a better solution.
The common OOP approach (or generally speaking “divide in components and conquer”) works in real life for trivial cases only. A component, if put in a complex context, starts to depend on things external to the local model, such as an other component state and a history of interactions.
The closer an interface comes to a really appropriate thing the more intertwined their many-to-many relations become. The actual complexity is been accumulated in the information management, in the gigantic heap of behaviour and influence nuances.
Of course, one does not simply fix the web with a single blog post, but we may prescribe the web a healthy diet which is the functional programming, the ancestral wisdom.
The “functional programming” itself is (as any ultra modern trend) a pretty general and blurry term. That is for the purpose of a holly wars made easy on the Internets. But the actual functional tricks are very focused and fairly useful.
You may call a function pure if it evaluates without any observable side effect such as console output, application state change, network requests. Usually, the pureness is declared at a conventional level, but Haskell happens too. This kind of functions is safe to call in any way, anywhere, any number of times.
Adjacent term is a “referential transparency”. Functions of this class do not depend on a global state but on their arguments only. The result of such a function is safe to cache.
Pure referentially transparent functions make a code simpler to read (graphically, where the data comes from and where it goes) and to test (no need to set up an environment).
Functional programmers did notice that the most part of an application code could be easily expressed with pure referentially transparent functions. The imperative programming still remains handy at the level of library algorithms. Nonpure functions go outside of a core and become highly local, which simplifies the effects tracking.
We all have been trained by OOP to store data and code together, but only few ask themselves if it isn't a sin. As a matter of fact programs are all about data: they take something (seven) and transform to something else (forty two).
It is extremely handy to have the data open and universally available, one can use them in any different way, not exclusively the way the author thought of. Even though the program may not have been run yet, but data is still there available.
Immutability is widely know thanks to strings. Once a string is created it could not be modified in future. But a new one is allowed to be created with, say, a concatenation. The old one remains intact and available as it is (with exception for C/C++, these guys like it the hard way).
The same approach is applicable to collections: lists, symbol tables, sets, structures. Adding a new element does not push to an immutable list, but creates a new list with one element more.
It is reasonable that immutable structures are more expensive in use, but not lethally. Good implementations (persistent data structures) reuse the “previous” state parts in a way the overall expense tends to be low:
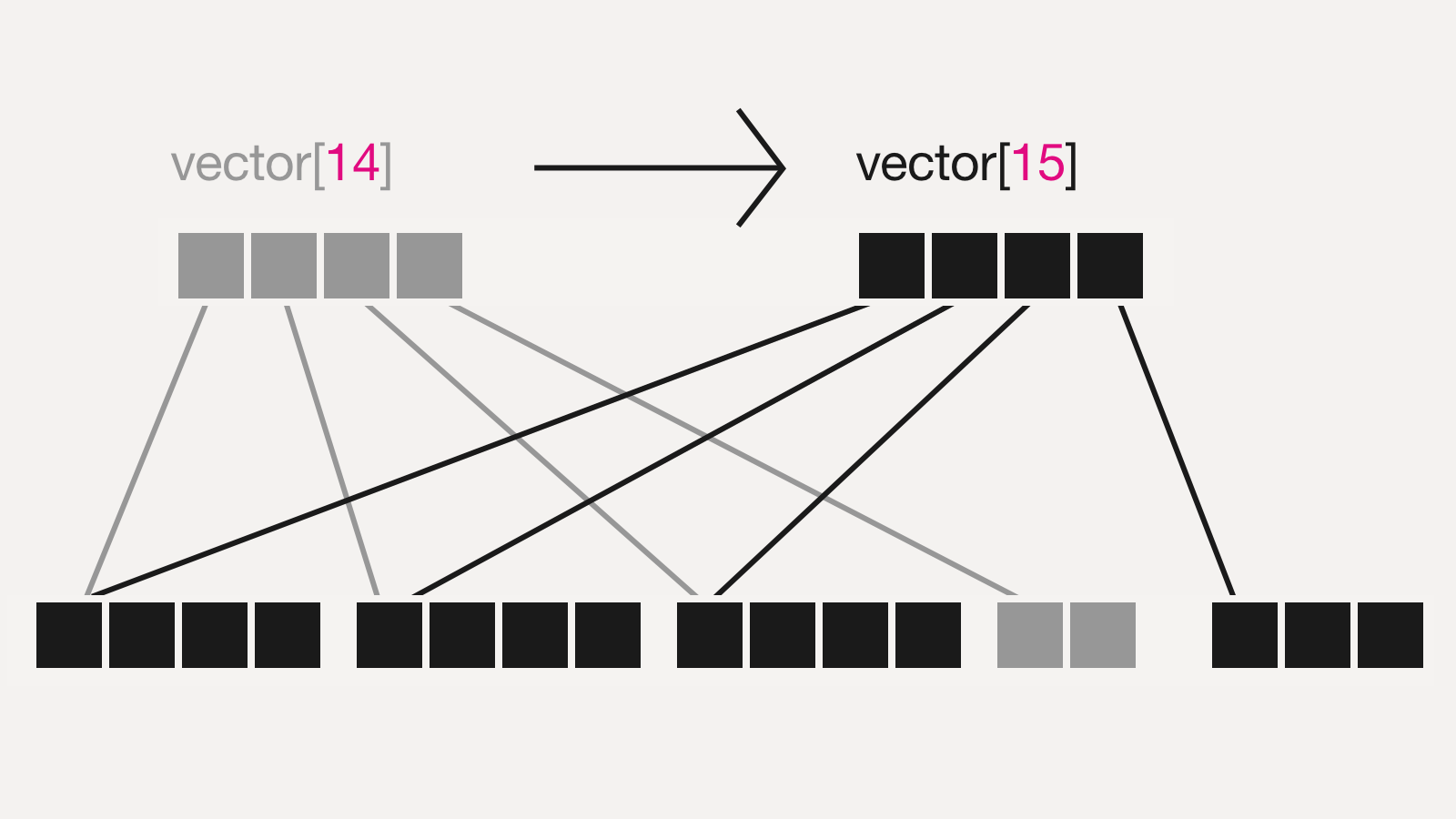
Immutability does rule in a multithreaded environment and so it does in a single threaded one too. It vastly simplifies reading of a code (easier to track an evolution of entities, all modifications are clearly visible) and protects from a whole class of errors like “made a change, got entangled, have forgotten”.
Laziness is a technique to postpone a calculation till it is actually needed. Instead of the immediate answer the function may return a recipe for getting the answer in hope that the caller will address the issue itself. Used mostly for calculations optimisation.

Let's now take a look at how to apply all of the things spoken to the initial target: web interfaces.
A traditional web interface is a single huge, complex, globally mutable DOM tree:

While it looks like an application is working properly it actually does change it's tree uncontrollably from all possible directions:

That is how a functional programmer's nightmare might look like: death-damp, soul-chilling terror, midnight cry, element.appendChild().
Suspect we have got a DOM tree immutable and not global. Suspect the DOM tree is just an immutable value. With that suspected our application turns into a pure function transforming one DOM tree to another:

So far so good: the application is ready for unit testing then. To test if a panel hides when clicked it's enough to just create DOM three with the panel, pass the DOM to our function, and then check if the returned DOM is lacking the panel. No need for booting up a browser and then clicking the application to get the proper state, just run a googol of threads and test.
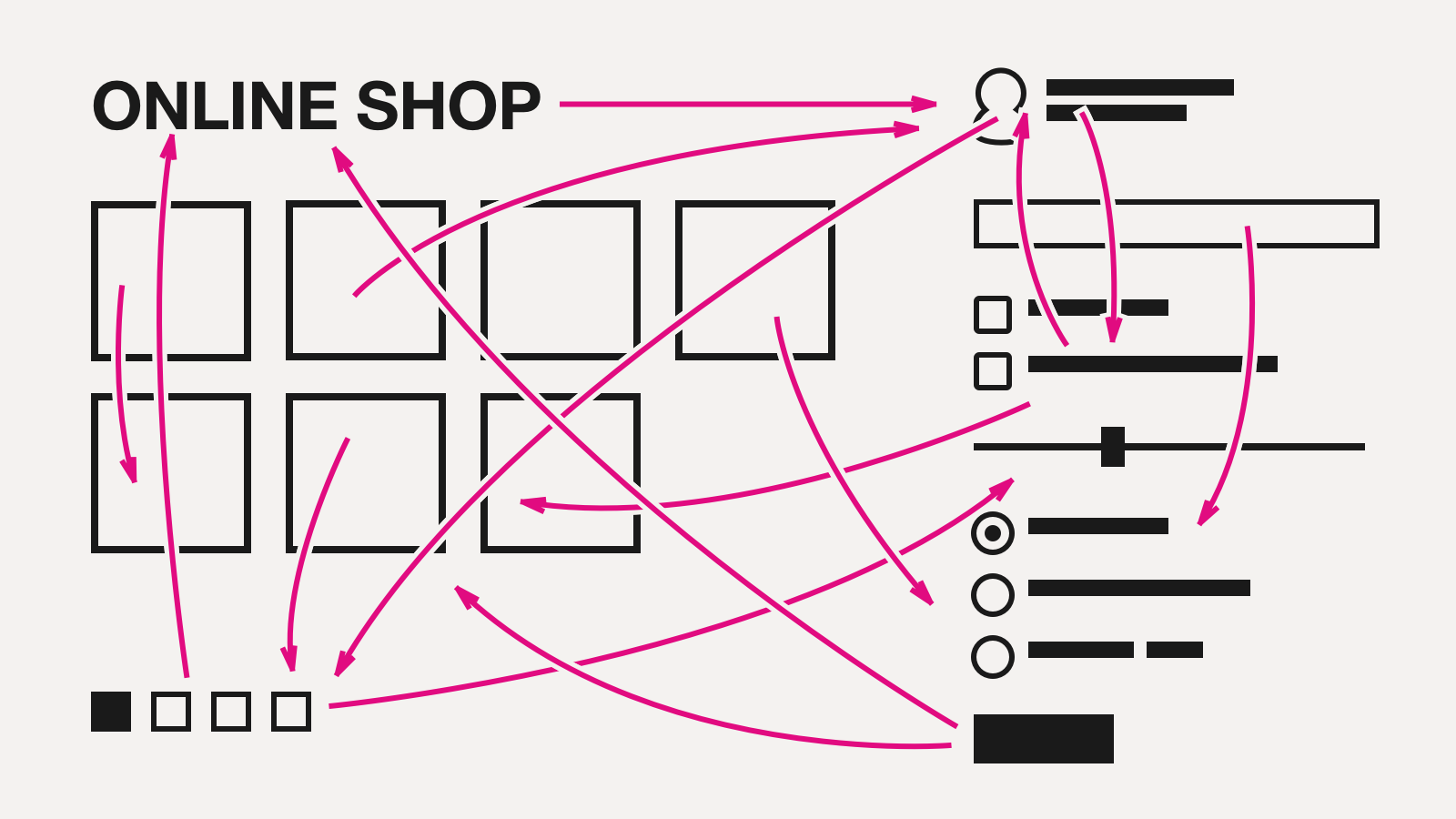
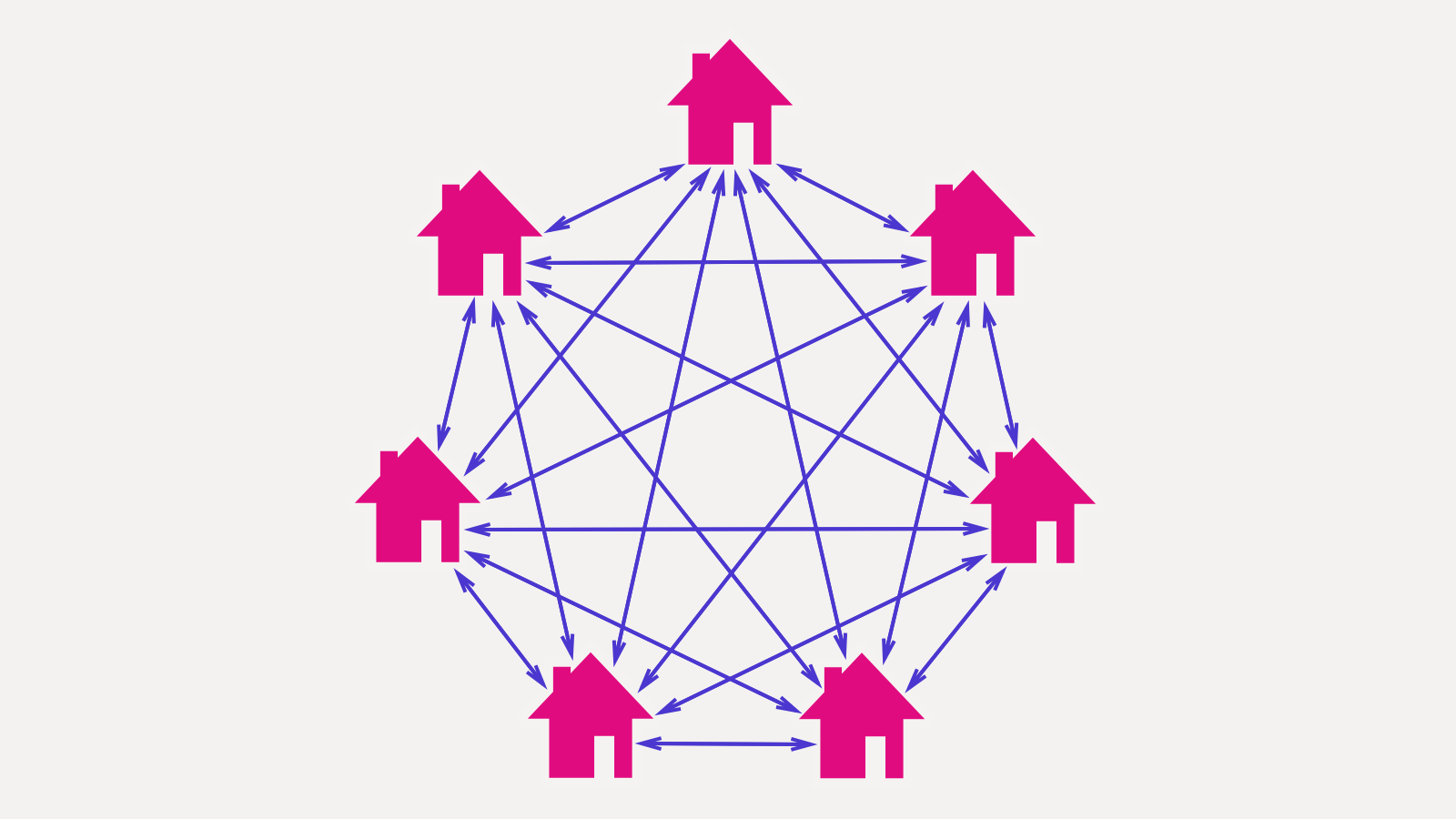
Now it is the complexity time. For N states of a DOM tree we need to write N² functions transitioning each state in each other state. Adding one new state requires N more functions translating to the new state, plus N more translating from the new state. In reality the web on the picture will be less dense, but the complexity function still is not linear:
In real life that hardly happens, but happens in programming – model to the rescue. We can reduce our application to a function which translates model to a DOM tree:
Different models give different trees:
All the logic happens on a level of transitions between the model states. The actual DOM tree transitions should be offloaded to a library:
This puts on some structure and sensitively reduces the amount of code working with DOM: from N² to N:
Attentive reader could notice that we have the problem reduced from DOM transitions to model state transitions. This is correct. And also correct is a reduction of the number of arrows on the picture. Swindled we feel.
In practice the model gets assembled much simpler and logically compared to the corresponding DOM tree. Model consists of less details, state transitions are trivial, no corner cases to concentrate on. That is, the picture structurally looks as having more details, but in practice it makes the code simpler.
Until now we were talking about widely know things. React and other virtual DOM based frameworks work roughly like this. Still, it is enough for a functional programming to blossom out: immutable DOM (actually, once-only – it is trashed instantly after been generated, which makes it effectively immutable), the rendering function if pure (React requires a freedom to decide where, when and how many times to call the function), and no global state been used.
And this is just a beginning. Lets push to the limits and declare the model immutable too:

Now the application logic could be expressed as a pure function: any state transition takes an old model and based on it generates a new one.
Immutable model gives a key to a lazy rendering. Immutable structure cannot be silently changed deep inside: it requires an in depth search, then a change, and then a careful repacking of everything back. That's why it is instantly fast to check if a model is dirty: just compare the references.
Since a model is rarely changed entirely and an application components depend on different parts of the model it is easy to calculate which parts should be re-rendered and which remain as they were. In React this optimisation (shouldComponentUpdate) is disabled by default and should be enabled manually at your own risk. For immutable arguments it is safe to enabled it everywhere. This way the actual rendering becomes lazy: the interesting parts only would be calculated while the rest parts remain untouched as a calculation recipe.
As a bonus the immutable model grants a conservation of history. Old model references remain valid, and been saved in a list could be played back and forth in history.
Lets take an overview of a whole architecture:
An application consists of a single current model, stack of model history and a rendering function translating the model to a DOM. As far as rendering function doesn't care where the model comes from it is easy to make a preview of previous history states and implement an undo by Ctrl+Z.
Even further, since the rendering function is indeed neutral to the source of a model it is possible to amend the architecture with a speculative model: all the previews, in-progress operations, uncommitted settings, etc. could be rendered by just calculating how would the model look like in that case. A speculative model is never saved, it is calculated on-the-fly and is sent to the rendering function only once.
This video shows a history stack (at bottom left) with a preview of previous states and undo functionality. Shapes have not been finished yet are rendered via speculative model:
The model history is just a pure data, which means we can make a data query on them.
Atomic.io is able to show a history of any particular object. Substantially, the framework builds an object history and merges the old versions into the current model:
The beauty of a separate model shows itself in an elegant architecture separation into loosely coupled layers. Rendering knows nothing about client-server synchronisation, server knows nothing about client-side caching, and so on. A model could be run on the server side separately from a render. All of the parts a deeply indifferent to the source of a model and who is also observing it. This is a quality worth fighting for.
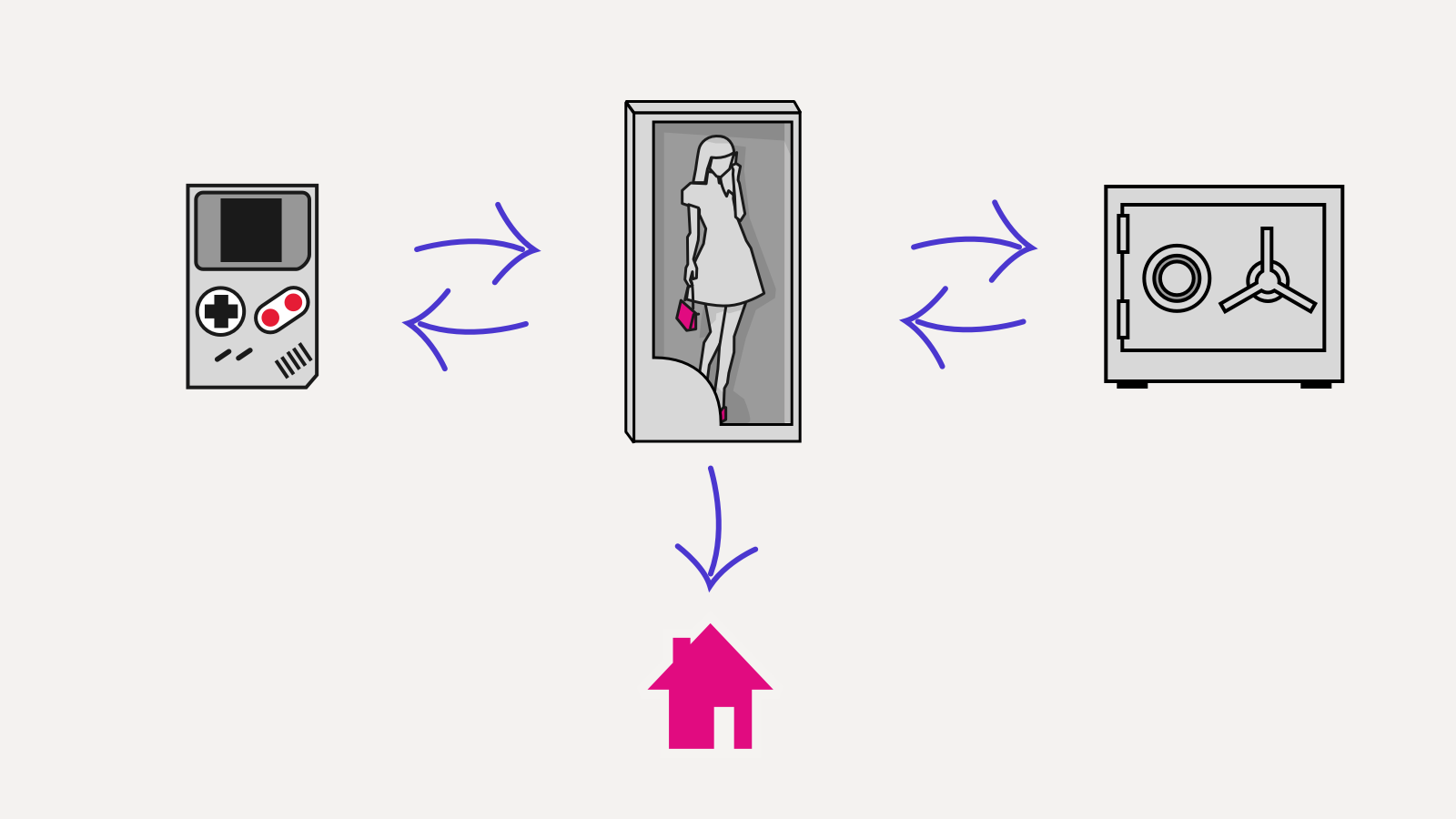
Another example of an immutable model usefulness: concurrent editing of a shared document. This kind of architecture uses Event Sourcing: a model is a result of folding of all the previous events had happened to it (which is a functional programming concept too):
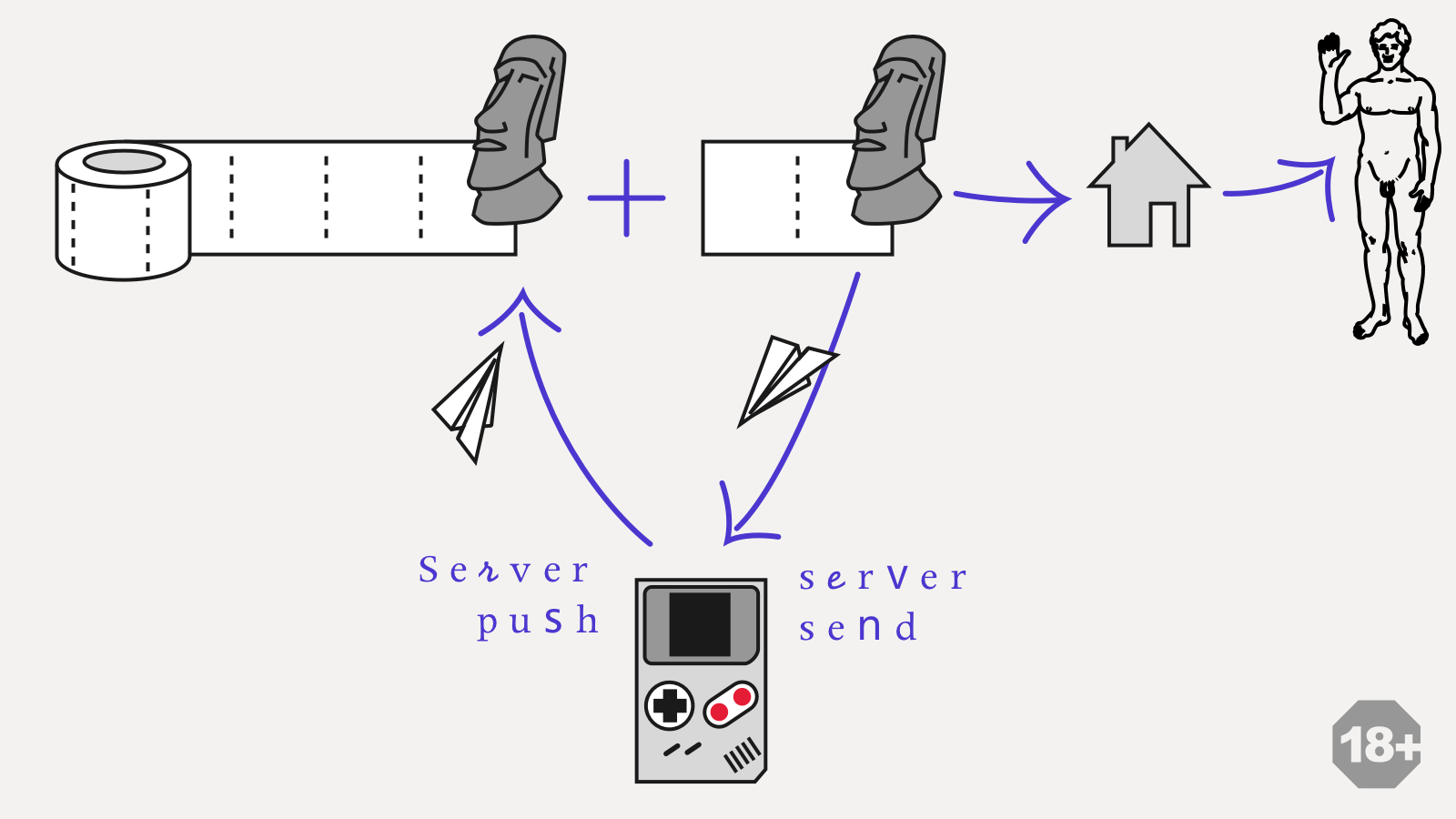
We store two event logs: local one and second one approved by a server. All the local events first hit the local log. Based on the local log the local model is calculated and then gets rendered. It delivers an instant feedback and an offline work.
Behind the scenes – independently and in parallel – local log tries to synchronise itself with the server log. Once events from the local log get approved by the server the local log gets cleared and all the approved events get applied to an approved model. This guaranties identical logs on all clients. Client gets automatically notified about the events from other clients: server just pushes them to an approved log immediately.
This architecture requires a model snapshots to be stored and used to re-calculate the most recent state without breaking anything.
Even more crazy thing: time traveling debugging:
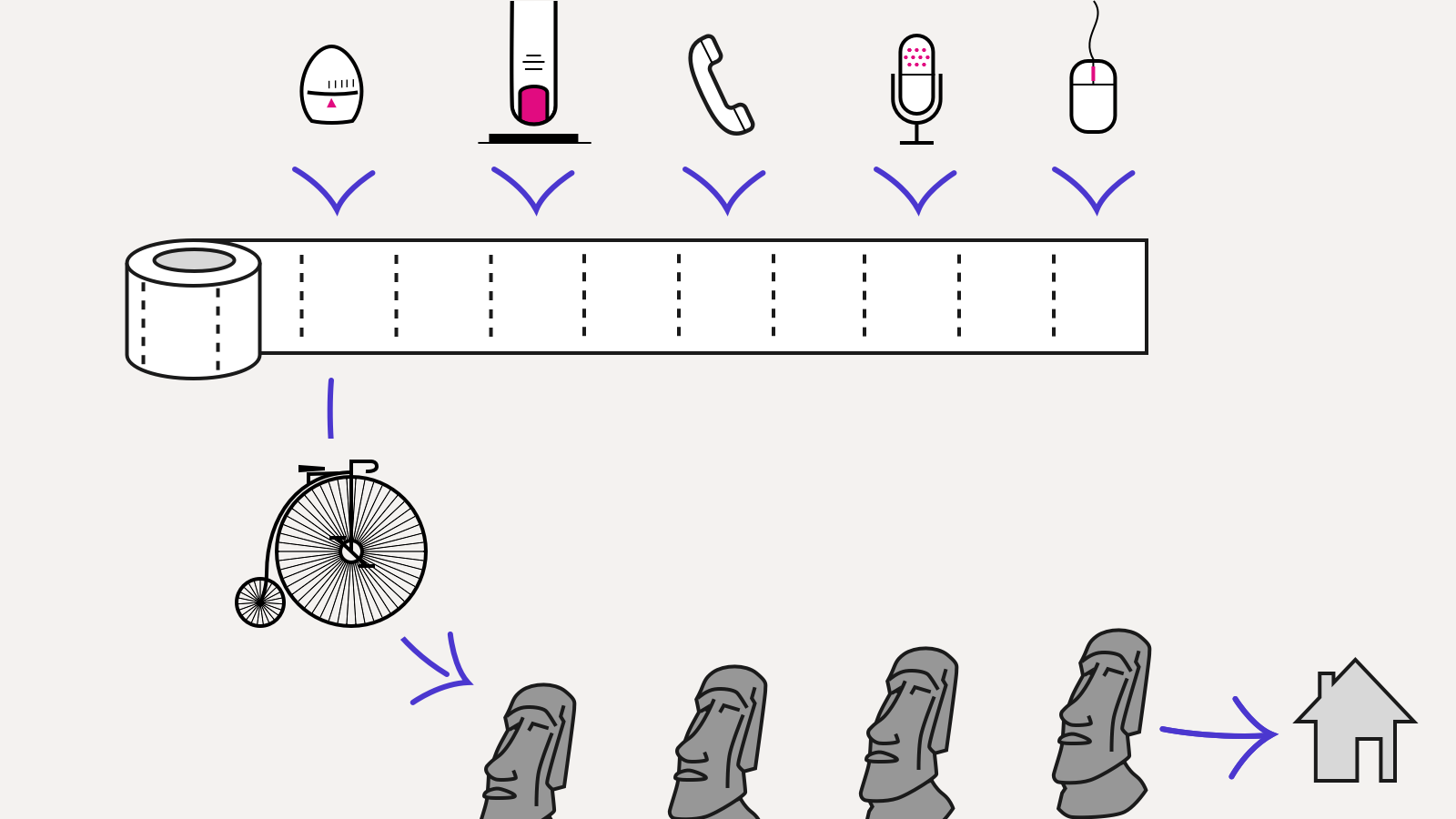
This is also is a way of event sourcing but with events been recorded on a very low level (all the external sources: user input, timers, network) and only then hit the application code.
Such a separation to a (highly pure) data and a code allows to serialise the application session, then send it for recreating the same session elsewhere. What more important is that the code might be changed and then run to see how the same session behaves with this new code. The example based on the Elm platform:
This concept requires a serious discipline (or a technology providing it), but on the other hand it grants enormous benefits for everyday applications. It is also useful in application support: got a bug report with an event log, fixed the bug, played back the evens to ensure bug is gone, and then enjoy a bug free evening.
Thus we want it. And we want it now. How to?
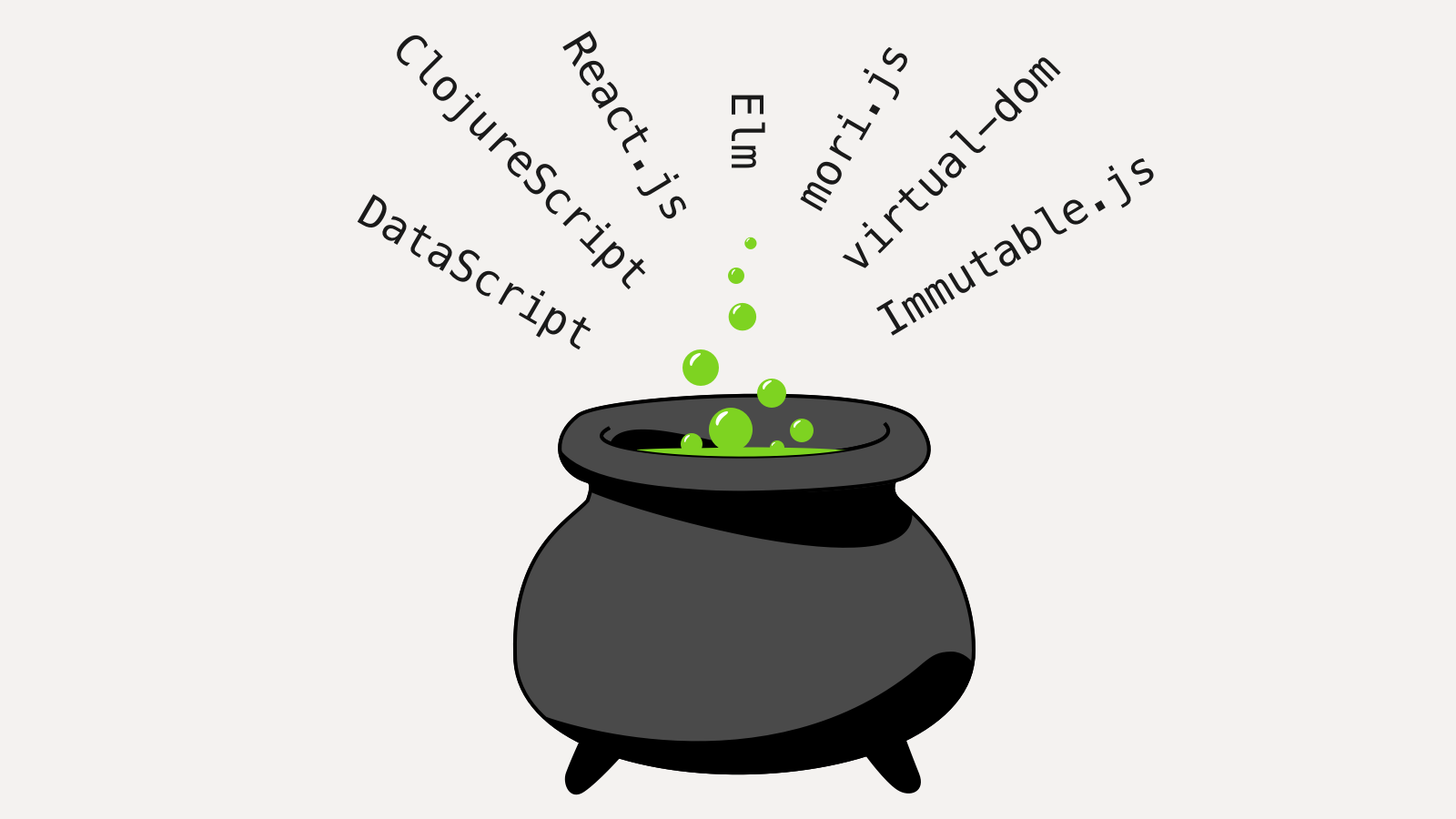
The must have are: a virtual DOM implementation (react.js, virtual-dom/mercury) and an immutable structures library (mori.js, immutable.js).
To specially mention I would like ClojureScript: it is a mature LISP dialect compilable to JavaScript. It is functional with immutable data structures by default, what's why it is so pleasurable to build such things using it. The most part of the ideas described here took start in its very ecosystem from where has been pilfered by imitators.

Also, the Elm platform was mentioned: it is yet an experimental project which aims to guarantee strictness and pureness providing most of the things we talked about, for free.

Few examples of projects built upon the described architectures:
Examples from absolutely different fields: starting from an ordinary web-site with a page/links interface (Prismatic: ClojureScript, Om), through a middle complexity interface Continuous Integration (CircleCI: ClojureScript, Om) to a prototyping platform (Precursor: ClojureScript, Om, DataScript) and ending with a web-based graphical editor (Atomic: JS, React, Immutable.js).
Functional programming has already come to mainstream and proven doing well. A virtual DOM and immutable structures seemingly are the common things waiting for us in the near future in all interfaces: from a cash machine to a kettle. I would recommend to stop waiting until W3C approves the Virtual DOM specification for browser vendors but jump into this train right now.
See also: The Future of JavaScript MVC Frameworks

Translated by Peter Leonov.